
 English
English
Różnica (roz)
Difference
Memory limit: 32 MB
A word consisting of  lower-case letters of the English alphabet ('a'-'z') is given.
We would like to choose a non-empty contiguous (i.e. one-piece) fragment
of the word so as to maximise the difference in the number of occurrences
of the most and the least frequent letter in the fragment.
We are assuming that the least frequent letter has to occur at least once in
the resulting fragment.
In particular, should the fragment contain occurrences of only one letter,
then the most and the least frequent letter in it coincide.
lower-case letters of the English alphabet ('a'-'z') is given.
We would like to choose a non-empty contiguous (i.e. one-piece) fragment
of the word so as to maximise the difference in the number of occurrences
of the most and the least frequent letter in the fragment.
We are assuming that the least frequent letter has to occur at least once in
the resulting fragment.
In particular, should the fragment contain occurrences of only one letter,
then the most and the least frequent letter in it coincide.
Input
The first line of the standard input holds one integer  (
(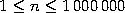 ) that denotes the length of the word.
The second line holds a word consisting of
) that denotes the length of the word.
The second line holds a word consisting of  lower-case letters
of the English alphabet.
lower-case letters
of the English alphabet.
In tests worth at least 30% of the points it additionally holds that 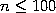 .
.
Output
The first and only line of the standard output is to hold a single integer, equal to the maximum difference in the number of occurrences of the most and the least frequent letter that is attained in some non-empty contiguous fragment of the input word.
Example
For the input data:
10 aabbaaabab
the correct result is:
3
Explanation of the example: The fragment that attains the difference of 3 in the number of occurrences of a and b is aaaba.
Task author: Jacek Tomasiewicz.