
 English
English
Różnica (roz)
Różnica
Limit pamięci: 32 MB
Mamy dane słowo złożone z  małych liter alfabetu angielskiego 'a'-'z'.
Chcielibyśmy wybrać pewien niepusty, spójny (tj. jednokawałkowy) fragment tego słowa, w taki sposób,
aby różnica pomiędzy liczbą wystąpień najczęściej i najrzadziej występującej w tym fragmencie litery była jak największa.
Zakładamy przy tym, że najrzadziej występująca litera w wynikowym fragmencie słowa musi mieć w tym fragmencie
co najmniej jedno wystąpienie.
W szczególności, jeżeli fragment składa się tylko z jednego rodzaju liter, to najczęstsza i najrzadsza litera
są w nim takie same.
małych liter alfabetu angielskiego 'a'-'z'.
Chcielibyśmy wybrać pewien niepusty, spójny (tj. jednokawałkowy) fragment tego słowa, w taki sposób,
aby różnica pomiędzy liczbą wystąpień najczęściej i najrzadziej występującej w tym fragmencie litery była jak największa.
Zakładamy przy tym, że najrzadziej występująca litera w wynikowym fragmencie słowa musi mieć w tym fragmencie
co najmniej jedno wystąpienie.
W szczególności, jeżeli fragment składa się tylko z jednego rodzaju liter, to najczęstsza i najrzadsza litera
są w nim takie same.
Wejście
Pierwszy wiersz standardowego wejścia zawiera jedną liczbę całkowitą  (
(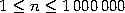 ), oznaczającą długość słowa.
Drugi wiersz zawiera słowo składające się z
), oznaczającą długość słowa.
Drugi wiersz zawiera słowo składające się z  małych liter alfabetu angielskiego.
małych liter alfabetu angielskiego.
W testach wartych przynajmniej 30% punktów zachodzi dodatkowy warunek 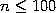 .
.
Wyjście
Pierwszy i jedyny wiersz standardowego wyjścia powinien zawierać jedną liczbę całkowitą, równą maksymalnej wartości różnicy między liczbą wystąpień najczęściej i najrzadziej występującej litery, jaką możemy znaleźć w pewnym spójnym fragmencie danego słowa.
Przykład
Dla danych wejściowych:
10 aabbaaabab
poprawną odpowiedzią jest:
3
Wyjaśnienie do przykładu: Fragment słowa, dla którego różnica między liczbą liter a i b wynosi 3, to aaaba.
Autor zadania: Jacek Tomasiewicz.